在XML技术里,可以编写一个文档来约束一个XML文档的书写规范,这称之为XML约束,常用的约束技术:
1. XML DTD
2. XML Schema
#DTD
##DTD格式
DTD(Document Type Definition),全称为文档类型定义。 DTD文件应使用UTF-8或Unicode。格式如下:
###外部文件

#PCDATA:放置字符数据
###内部编写方式
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| <?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<!DOCTYPE 书架 [
<!ELEMENT 书架 (书+)> // 如果写EMPTY - 空元素,不能有子标签 ANY - 任何子标签
<!ELEMENT 书 (书名,作者,售价)>
<!ELEMENT 书名 (
<!ELEMENT 作者 (
<!ELEMENT 售价 (
]>
<书架>
<书>
<书名>Java就业培训教程</书名>
<作者>张孝祥</作者>
<售价>39.00元</售价>
</书>
...
</书架>
|
##编程验证DTD
编写方式如下:
外部文件方式:validate.html
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| <html>
<head>
<script>
var xmldoc = new ActiveXObject("Microsoft.XMLDOM"); // 创建XML文档解析对象 IE5以上内置 Microsoft.XMLDOM 解析工具
xmldoc.validateOnParse=true; // 开启XML校验
xmldoc.load("catalog.xml"); // 装载XML文件
/*打印错误信息*/
document.write("错误的原因:" + xmldoc.parseError.reason + "<br/>");
document.write("错误的行号:" + xmldoc.parseError.line + "<br/>");
</script>
</head>
<body>
</body>
</html>
|
##引用DTD约束
XML中使用DOCTYPE声明语句来指明所遵循的DTD文件:
1
2
| <!DOCTYPE 文档根结点 SYSTEM "DTD文件的URL"> // 引用本地DTD文件
<!DOCTYPE 文档根结点 PUBLIC "DTD名称" "DTD文件的URL"> // 引用公共文件(比如某网站的DTD文件)
|
##DTD约束语法
###元素定义
1
2
3
4
5
6
7
| 格式:<!ELEMENT 元素名称 元素类型>
如为元素内容:则需要使用()括起来,如
<!ELEMENT 书架 (书名,作者,售价)>
<!ELEMENT 书名 (
如为元素类型,则直接书写,DTD规范定义了如下几种类型:
EMPTY:用于定义空元素,例如<br/> <hr/>
ANY:表示元素内容为任意类型
|
###元素组成
1
2
3
4
5
6
7
8
| <!ELEMENT MYFILE (TITLE,AUTHOR,EMAIL)> // 内容与此什么顺序一致
<!ELEMENT MYFILE (TITLE|AUTHOR|EMAIL)> // 只能出现其中一个
<!ELEMENT MYFILE (TITLE|AUTHOR|EMAIL)>* //出现一个或者多个
+: 一次或多次 (书+)
?: 0次或一次 (书?)
*: 0次或多次 (书*)
eg:
<!ELEMENT MYFILE ((TITLE*, AUTHOR?, EMAIL)* | COMMENT)>
|
###属性定义
####属性定义方式
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| 属性格式:
<!ATTLIST 元素名
属性名1 属性值类型 设置说明
属性名2 属性值类型 设置说明
……
>
属性说明:
直接使用默认值:在 XML 中可以设置该值也可以不设置该属性值。若没设置则使用默认值。
eg:
<!ATTLIST 页面作者
姓名 CDATA
年龄 CDATA
联系信息 CDATA
网站职务 CDATA
个人爱好 CDATA "上网" // 默认值:上网
>
|
####常用属性值类型
- CDATA 文本字符串
- ENUMERATED 枚举型
eg:1
2
3
4
5
6
7
8
9
10
| <?xml version = "1.0" encoding="GB2312" standalone="yes"?>
<!DOCTYPE 购物篮 [
<!ELEMENT 肉 EMPTY>
<!ATTLIST 肉 品种 ( 鸡肉 | 牛肉 | 猪肉 | 鱼肉 ) "鸡肉">
]>
<购物篮>
<肉 品种="鱼肉"/>
<肉 品种="牛肉"/>
<肉/>
</购物篮>
|
ID只能由字母或者下划线开头.eg:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| <?xml version = "1.0" encoding="GB2312" ?>
<!DOCTYPE 联系人列表[
<!ELEMENT 联系人列表 ANY>
<!ELEMENT 联系人(姓名,EMAIL)>
<!ELEMENT 姓名(
<!ELEMENT EMAIL(
<!ATTLIST 联系人 编号 ID
]>
<联系人列表>
<联系人 编号="a1">
<姓名>张三</姓名>
<EMAIL>zhang@it315.org</EMAIL>
</联系人>
<联系人 编号="a2">
<姓名>李四</姓名>
<EMAIL>li@it315.org</EMAIL>
</联系人>
</联系人列表>
|
在DTD文件中,语句用于定义一个实体(相当于一个变量).
#####引用实体
引用实体主要在XML文件中使用,格式如下:
1
2
3
4
5
|
<!ENTITY copyright “I am a programmer">
……
©right;//XML中以此形式引用
|
#####参数实体
参数实体主要为DTD文件自己使用,格式如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
| <!ENTITY % 实体名称 "实体内容" >
<!ENTITY % TAG_NAMES "姓名 | EMAIL | 电话 | 地址">
<!ELEMENT 个人信息 (%TAG_NAMES; | 生日)>
<!ELEMENT 客户信息 (%TAG_NAMES; | 公司名)>
<!ENTITY % common.attributes
" id ID #IMPLIED
account CDATA #REQUIRED " >
...
<!ATTLIST purchaseOrder %common.attributes;>
<!ATTLIST item %common.attributes;>
|
##xml编程
XML CRUD - create read update delete。JAXP包,J2SE的一部分,包含xml解析器对象。
###XML解析方式
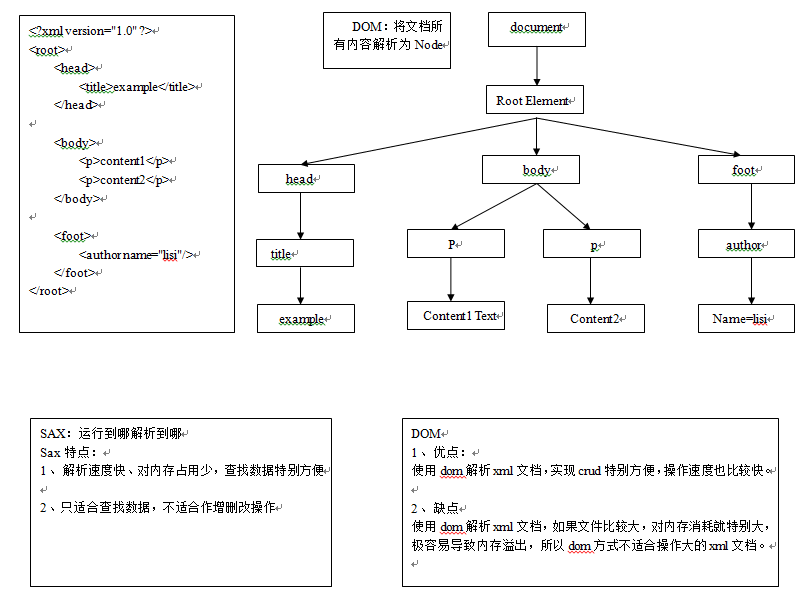
XML解析方式分为两种:DOM(w3c推荐) 和 SAX(只能做查询)。两种区别如下:
###使用JAXP包进行DOM解析
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
| public class Demo {
/**使用jaxp操作xml文档
* @param args
* @throws ParserConfigurationException
* @throws IOException
* @throws SAXException
*/
public static void main(String[] args) throws ParserConfigurationException, SAXException, IOException {
//1.获取DOM解析器的工厂
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
//2.得到DOM解析器对象
DocumentBuilder builder = factory.newDocumentBuilder();
//3.解析xml文档,得到代表文档的document
Document document = builder.parse(new File("src/book1.xml"));
//4.遍历所有节点
list(document);
}
//得到售价结点的值
@Test
public void read() throws Exception{
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
Document document = builder.parse(new File("src/book.xml"));
NodeList list = document.getElementsByTagName("售价");
Node price = list.item(0);
String value = price.getTextContent();
System.out.println(value);
}
//修改结点的值:<售价>39.00元</售价>改为109
@Test
public void update() throws Exception{
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
Document document = builder.parse(new File("src/book1.xml"));
Node price = document.getElementsByTagName("售价").item(0);
price.setTextContent("109");
//把内存中的document写到xml文档
TransformerFactory tf = TransformerFactory.newInstance();
//得到转换器
Transformer ts = tf.newTransformer();
ts.transform(new DOMSource(document), new StreamResult(new File("src/book1.xml")));
}
//向指定节点中增加孩子节点(售价节点)
@Test
public void add() throws Exception{
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
Document document = builder.parse(new File("src/book1.xml"));
//创建需要增加的节点
Node price = document.createElement("售价");
price.setTextContent("59元");
//得到需要增加的节点的父亲
Node parent = document.getElementsByTagName("书").item(0);
//把需要增加的节点挂到父结点上
parent.appendChild(price);
TransformerFactory tf = TransformerFactory.newInstance();
Transformer ts = tf.newTransformer();
ts.transform(new DOMSource(document), new StreamResult(new File("src/book1.xml")));
}
//向指定位置上插入售价节点
@Test
public void add2() throws Exception{
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
Document document = builder.parse(new File("src/book1.xml"));
Node node = document.createElement("售价");
node.setTextContent("39元");
Node parent = document.getElementsByTagName("书").item(0);
parent.insertBefore(node, document.getElementsByTagName("书名").item(0));
TransformerFactory tf = TransformerFactory.newInstance();
Transformer ts = tf.newTransformer();
ts.transform(new DOMSource(document), new StreamResult(new File("src/book1.xml")));
}
//删除xml文档的售价结点
@Test
public void delete() throws Exception{
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
Document document = builder.parse(new File("src/book1.xml"));
Node node = document.getElementsByTagName("售价").item(2);
node.getParentNode().removeChild(node);
TransformerFactory tf = TransformerFactory.newInstance();
Transformer ts = tf.newTransformer();
ts.transform(new DOMSource(document), new StreamResult(new File("src/book1.xml")));
}
//操作xml文档属性
@Test
public void updateAttribute() throws Exception{
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
Document document = builder.parse(new File("src/book1.xml"));
//操作xml文档的元素时,一般都把元素当作node对象,但是程序员如果发现node不好使时,就应把node强转成相应类型
Node node = document.getElementsByTagName("书").item(0);
Element book = null;
if(node.getNodeType()==Node.ELEMENT_NODE){ //在作结点转换之前,最好先判断结点类型
book = (Element)node;
}
book.setAttribute("name", "yyyyyyy");
book.setAttribute("password", "123");
book.removeAttribute("password");
TransformerFactory tf = TransformerFactory.newInstance();
Transformer ts = tf.newTransformer();
ts.transform(new DOMSource(document), new StreamResult(new File("src/book1.xml")));
}
//遍历
public static void list(Node node){
if(node.getNodeType()==Node.ELEMENT_NODE){
System.out.println(node.getNodeName());
}
NodeList list = node.getChildNodes();
for(int i=0;i<list.getLength();i++){
Node child = list.item(i);
list(child);
}
}
}
|
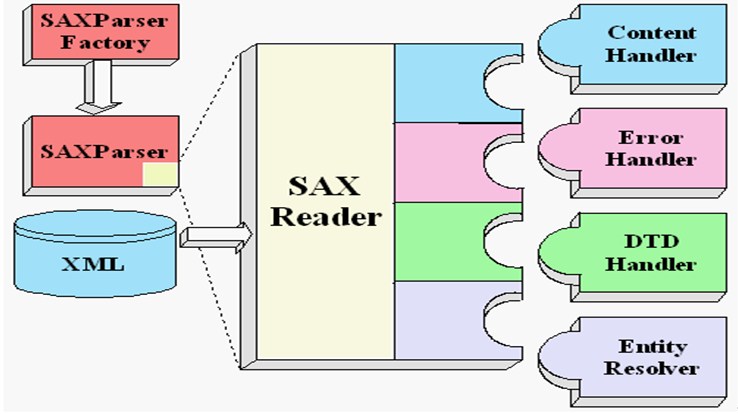
###SAX解析
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
|
public class Demo1 {
/**
*sax方式解析book1.xml文件
* @throws SAXException
* @throws ParserConfigurationException
* @throws IOException
*/
public static void main(String[] args) throws ParserConfigurationException, SAXException, IOException {
//1.创建sax工厂
SAXParserFactory factory = SAXParserFactory.newInstance();
//2.用工厂创建解析器
SAXParser sp = factory.newSAXParser();
//3.利用解析器得到reader
XMLReader reader = sp.getXMLReader();
//4.在解析xml文档之前,设置好事件处理器,事件处理器为程序员设计来对解析xml进行处理
reader.setContentHandler(new MyContentHandler2());
//5.利用reader读取 xml文档
reader.parse("src/book1.xml");
}
}
//得到xml文档内容的事件处理器,实现接口
class MyContentHandler implements ContentHandler{
public void startElement(String uri, String localName, String name, Attributes atts) throws SAXException {
System.out.println("当前解析到了:" + name + ",这个标签是开始标签");
for(int i=0;i<atts.getLength();i++){
String attname = atts.getQName(i);
String attvalue = atts.getValue(i);
System.out.println(attname + "=" + attvalue);
}
}
public void endElement(String uri, String localName, String name) throws SAXException {
System.out.println("当前解析到了:" + name + ",这个标签是结束标签");
}
public void characters(char[] ch, int start, int length) throws SAXException {
System.out.println("当前解析到了内容:" + new String(ch,start,length));
}
.... // 实现接口其他方法
}
//用于获取第一个售价节点的值:<售价>109</售价> ,用继承的方式实现事件处理器,不用对接口每个方法进行实现
class MyContentHandler2 extends DefaultHandler{
private boolean isOk = false;
private int index = 1;
@Override
public void characters(char[] ch, int start, int length) throws SAXException {
if(isOk==true && index==1){
System.out.println(new String(ch,start,length));
}
}
@Override
public void startElement(String uri, String localName, String name, Attributes attributes) throws SAXException {
if(name.equals("售价")){
isOk = true;
}
}
@Override
public void endElement(String uri, String localName, String name)
throws SAXException {
if(name.equals("售价")){
isOk = false;
index++;
}
}
}
|
##Dom4j解析
DOM4j中,获得Document对象的方式有三种:
1
2
3
4
5
6
7
8
9
|
SAXReader reader = new SAXReader();
Document document = reader.read(new File("input.xml"));
String text = "<members></members>";
Document document = DocumentHelper.parseText(text);
Document document = DocumentHelper.createDocument(); //创建根节点
Element root = document.addElement("members");
|
注意dom4j库及docs。参考XPath Tutorial
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
| public class Demo1 {
//读取xml文档数据:<书名>Java就业培训教程</书名>
@Test
public void read() throws Exception{
SAXReader reader = new SAXReader();
Document document = reader.read(new File("src/book1.xml"));
Element root = document.getRootElement();
Element bookname = root.element("书").element("书名");
System.out.println(bookname.getText());
}
//<书 name="yyyyyyy">
@Test
public void readAttr() throws Exception{
SAXReader reader = new SAXReader();
Document document = reader.read(new File("src/book1.xml"));
Element root = document.getRootElement();
String value = root.element("书").attributeValue("name");
System.out.println(value);
}
//向xml文档中添加<售价>19元</售价>
@Test
public void add() throws Exception{
SAXReader reader = new SAXReader();
Document document = reader.read(new File("src/book1.xml"));
Element price = DocumentHelper.createElement("售价");
price.setText("19元");
document.getRootElement().element("书").add(price);
// 将修改从内存中存入xml
OutputFormat format = OutputFormat.createPrettyPrint();
format.setEncoding("UTF-8");
XMLWriter writer = new XMLWriter(new FileOutputStream("src/book1.xml"),format);
writer.write(document); //utf-8
writer.close();
}
//修改:<售价>109</售价> 为209
@Test
public void update() throws Exception{
SAXReader reader = new SAXReader();
Document document = reader.read(new File("src/book1.xml"));
Element price = (Element) document.getRootElement().element("书").elements("售价").get(1);
price.setText("209元");
OutputFormat format = OutputFormat.createPrettyPrint();
format.setEncoding("UTF-8");
XMLWriter writer = new XMLWriter(new FileOutputStream("src/book1.xml"),format);
writer.write(document); //utf-8
writer.close();
}
//删除:<售价>109</售价>
@Test
public void delete() throws Exception{
SAXReader reader = new SAXReader();
Document document = reader.read(new File("src/book1.xml"));
Element price = (Element) document.getRootElement().element("书").elements("售价").get(0);
price.getParent().remove(price);
OutputFormat format = OutputFormat.createPrettyPrint();
format.setEncoding("UTF-8");
XMLWriter writer = new XMLWriter(new FileOutputStream("src/book1.xml"),format);
writer.write(document); //utf-8
writer.close();
}
//向指定位置增加售价结点
@Test
public void add2() throws Exception{
SAXReader reader = new SAXReader();
Document document = reader.read(new File("src/book1.xml"));
Element price = DocumentHelper.createElement("售价");
price.setText("19元");
List list = document.getRootElement().element("书").elements();
list.add(1, price);
OutputFormat format = OutputFormat.createPrettyPrint();
format.setEncoding("UTF-8");
XMLWriter writer = new XMLWriter(new FileOutputStream("src/book1.xml"),format);
writer.write(document); //utf-8
writer.close();
}
//XPATH 编写
@Test
public void findWithXpath() throws Exception{
SAXReader reader = new SAXReader();
Document document = reader.read(new File("src/book1.xml"));
Element e = (Element) document.selectNodes("//书名").get(1); // search 书名node 并获得第一个
System.out.println(e.getText());
}
@Test
public void findUser() throws Exception{
String username = "aaa";
String password = "1233";
SAXReader reader = new SAXReader();
Document document = reader.read(new File("src/users.xml"));
Element e = (Element) document.selectSingleNode("//user[@username='"+username+"' and @password='"+password+"']"); //search 匹配的用户名和密码 node
if(e!=null){
System.out.println("用户登陆成功!!");
}else{
System.out.println("用户名和密码不正确!!");
}
}
}
|
##XML schema
xml schema 也是一种定义和描述xml结构与内容的模式语言,其出现是为了克服DTD的局限性。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
| //File:book.xsd
<?xml version="1.0" encoding="UTF-8" ?>
//必须以 schema 开始和结束
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema" // 声明xs出处
targetNamespace="http://www. itcast.cn" // 声明指定一个名称空间 http://www. itcast.cn, 将xsd中所有节点绑定到此空间,然后xml就可以根据此URL(名称空间)告知解析器
elementFormDefault="qualified"> elementFormDefault指定schema属性都属于targetNamespace指定的名称空间
<xs:element name='书架' >
<xs:complexType>
<xs:sequence maxOccurs='unbounded' >
<xs:element name='书' >
<xs:complexType>
<xs:sequence>
<xs:element name='书名' type='xs:string' />
<xs:element name='作者' type='xs:string' />
<xs:element name='售价' type='xs:string' />
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:schema>
//File: book.xml
<?xml version="1.0" encoding="UTF-8"?>
<itcast:书架 xmlns:itcast="http://www.itcast.cn" //声明指定上xsd文件中定义的名称空间
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" // 指定下面schemaLocation属性出处
xsi:schemaLocation=“http://www.itcast.cn book.xsd"> // 指定名称空间的schema
<itcast:书>
<itcast:书名>JavaScript网页开发</itcast:书名>
<itcast:作者>张孝祥</itcast:作者>
<itcast:售价>28.00元</itcast:售价>
</itcast:书>
</itcast:书架>
b. 使用默认命名空间
<书架 xmlns="http://www.itcast.cn"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation=“http://www.itcast.cn book.xsd">
<书>
<书名>JavaScript网页开发</书名>
<作者>张孝祥</作者>
<售价>28.00元</售价>
</书>
<书架>
<?xml version="1.0" encoding="UTF-8"?>
<书架 xmlns="http://www.it315.org/xmlbook/schema"
xmlns:demo="http://www.it315.org/demo/schema"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.it315.org/xmlbook/schema http://www.it315.org/xmlbook.xsd //命名空间1
http://www.it315.org/demo/schema http://www.it315.org/demo.xsd"> //命名空间2
<书>
<书名>JavaScript网页开发</书名>
<作者>张孝祥</作者>
<售价 demo:币种=”人民币”>28.00元</售价>
</书>
</书架>
<?xml version="1.0" encoding="UTF-8"?>
<书架 xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="xmlbook.xsd">
<书>
<书名>JavaScript网页开发</书名>
<作者>张孝祥</作者>
<售价>28.00元</售价>
</书>
</书架>
|